
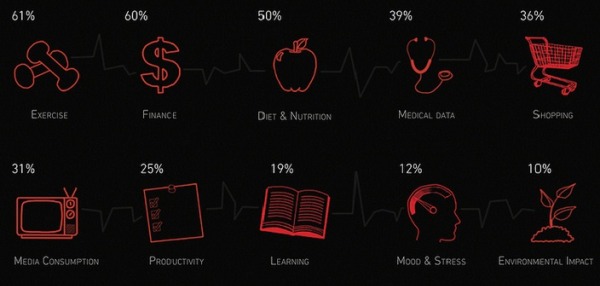
Big Data and the Quantified Self
Everything in our life right now is full of data; from the food that we eat to our physical routine. Known as the “quantified self”... Read More

Gambling and Big Data: A Safe Bet?
Marketing in 2014: every day, tracking software peers into consumers’ spending histories. Meanwhile, companies scour our personal information for any crumbs of data that might... Read More

The Connected Society
In May 2014, Big Data Week will launch the third edition of the festival with a narrative that will bring together the many strands and... Read More
A BIG Data Week in Malaysia
Asia: a huge, diverse, and rapidly changing society. One could even say it has high volume, variety, and velocity. Here in Malaysia we value a... Read More
Rise Of The Machines – Why Big Data Is Getting Bigger Every Day
Hundreds of terabytes. That’s the amount of Big Data being generated by multi-national corporations, every day. While terrifying for some, others see it as an... Read More
The Big Data Discovery Puzzle
By Kevin Long, Business Development Director, Teradata UK No matter what the industry, forming the intelligent discovery environment required to generate competitive advantage from big... Read More