

Why Hadoop Is Important In Handling Big Data?
This is a guest post written by Jagadish Thaker in 2013.
Hadoop is changing the perception of handling Big Data especially the unstructured data. Let’s know how Apache Hadoop software library, which is a framework, plays a vital role in handling Big Data. Apache Hadoop enables surplus data to be streamlined for any distributed processing system across clusters of computers using simple programming models. It truly is made to scale up from single servers to a large number of machines, each and every offering local computation, and storage space. Instead of depending on hardware to provide high-availability, the library itself is built to detect and handle breakdowns at the application layer, so providing an extremely available service along with a cluster of computers, as both versions might be vulnerable to failures.
Hadoop Community Package Consists of:
- File system and OS level abstractions
- A MapReduce engine (either MapReduce or YARN)
- The Hadoop Distributed File System (HDFS)
- Java ARchive (JAR) files
- Scripts needed to start Hadoop
- Source code, documentation and a contribution section
Activities performed on Big Data:
- Store – Big data need to be collected in a seamless repository, and it is not necessary to store in a single physical database.
- Process – The process becomes more tedious than traditional one in terms of cleansing, enriching, calculating, transforming, and running algorithms.
- Access – There is no business sense of it at all when the data cannot be searched, retrieved easily, and can be virtually showcased along the business lines.
Hadoop Distributed FileSystem (HDFS)
HDFS is designed to run on commodity hardware. It stores large files typically in the range of gigabytes to terabytes across different machines. HDFS provides data awareness between task tracker and job tracker. The job tracker schedules map or reduce jobs to task trackers with awareness in the data location. This simplifies the process of data management. The two main parts of Hadoop are data processing framework and HDFS. HDFS is a rack aware file system to handle data effectively. HDFS implements a single-writer, multiple-reader model and supports operations to read, write, and delete files, and operations to create and delete directories.
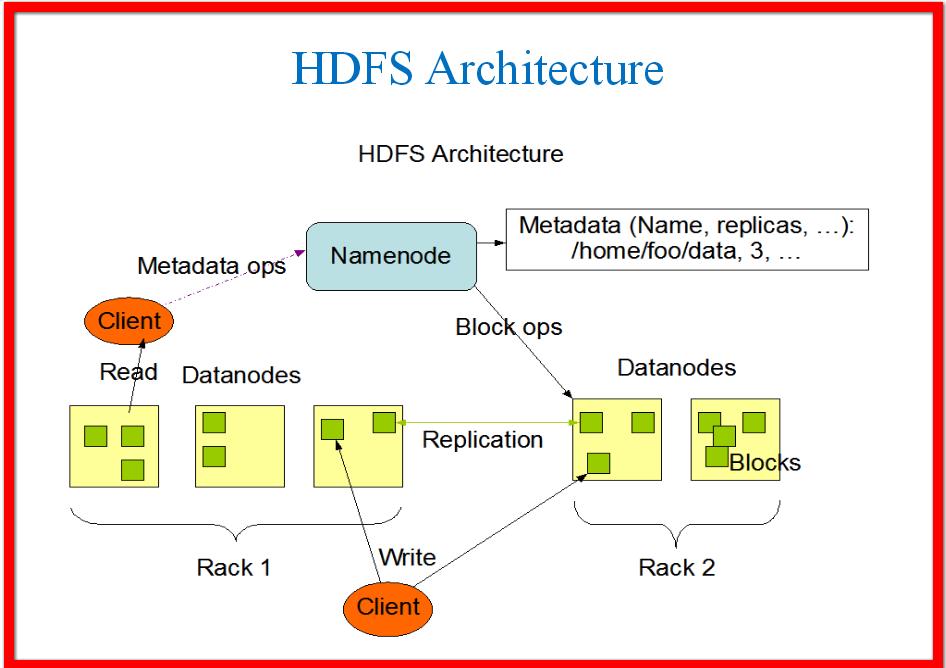
Assumptions and Goals
- In case of Hardware Failure: A core architectural goal of HDFS is detection of faults and quick, automatic recovery from them.
- Need Streaming Data Access: To run the application HDFS is designed more for batch processing rather than interactive use by users to streaming their data sets.
- Designed for Large Data Sets: HDFS is designed in such a way that it tuned to support large files and it provides big aggregate data bandwidth and scale to many nodes in a single cluster.
- Simple Coherency Model: HDFS applications need a write-once-read-many access model for files. A MapReduce application or a web crawler application fits perfectly with this model.
- Portability Issues: HDFS has been designed to be easily portable from one platform to another Across Heterogeneous Hardware and Software Platforms.
Data Processing Framework & MapReduce
The data processing framework is the tool used to process the data and it is a Java based system known as MapReduce. People get crazy when they work with it.
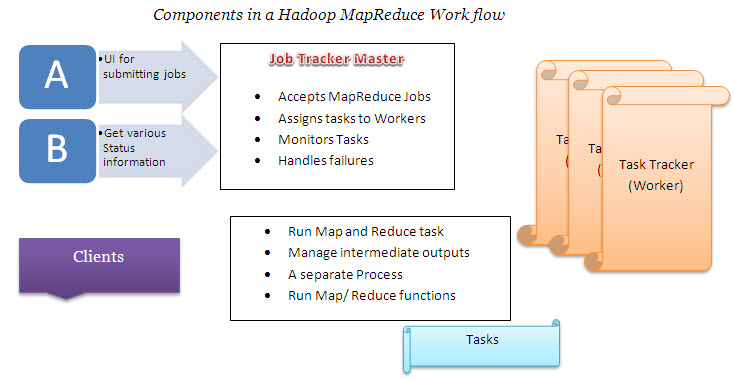
JobTracker and TaskTracker: the MapReduce Engine
Job Tracker Master handles the data, which comes from the MapReduce. Then it assigns tasks to workers, manages the entire process, monitors the tasks, and handles the failures if any. The JobTracker drives work out to available TaskTracker nodes in the cluster, striving to keep the work as close to the data as possible. As Job Tracker knows the architecture with all steps that has to be followed in this way, it reduces the network traffic by streamlining the racks and their respective nodes.
Scattered Across the Cluster
Here, the data is distributed on different machines and the work trends is also divided out in such a way that data processing software is housed on the another server. On a Hardtop cluster, the data stored within HDFS and the MapReduce system are housed on each machine in the cluster to add redundancy to the system and speeds information retrieval while data processing.
Cloud Brusting:
The private cloud journey will fall into line well using the enterprise wide analytical requirementshighlighted in this research, but executives must make sure that workload assessments are carried outrigorously understanding that risk is mitigated where feasible.
Big data is massive and messy, and it’s coming at you uncontrolled. Data are gathered to be analyzed to discover patterns and correlations that could not be initially apparent, but might be useful in making business decisions in an organization. These data are often personal data, which are useful from a marketing viewpoint to understand the desires and demands of potential customers and in analyzing and predicting their buying tendencies.
Organizational Architecture Need for an Enterprise: You can benefit by the enterprise architecture that scales effectively with development – and the rise of Big Data analytics means that this issue required to be addressed more urgently. IDC believes that these below use cases can be best mapped out across two of the Big Data dimensions – namely velocity and variety as outlined below.
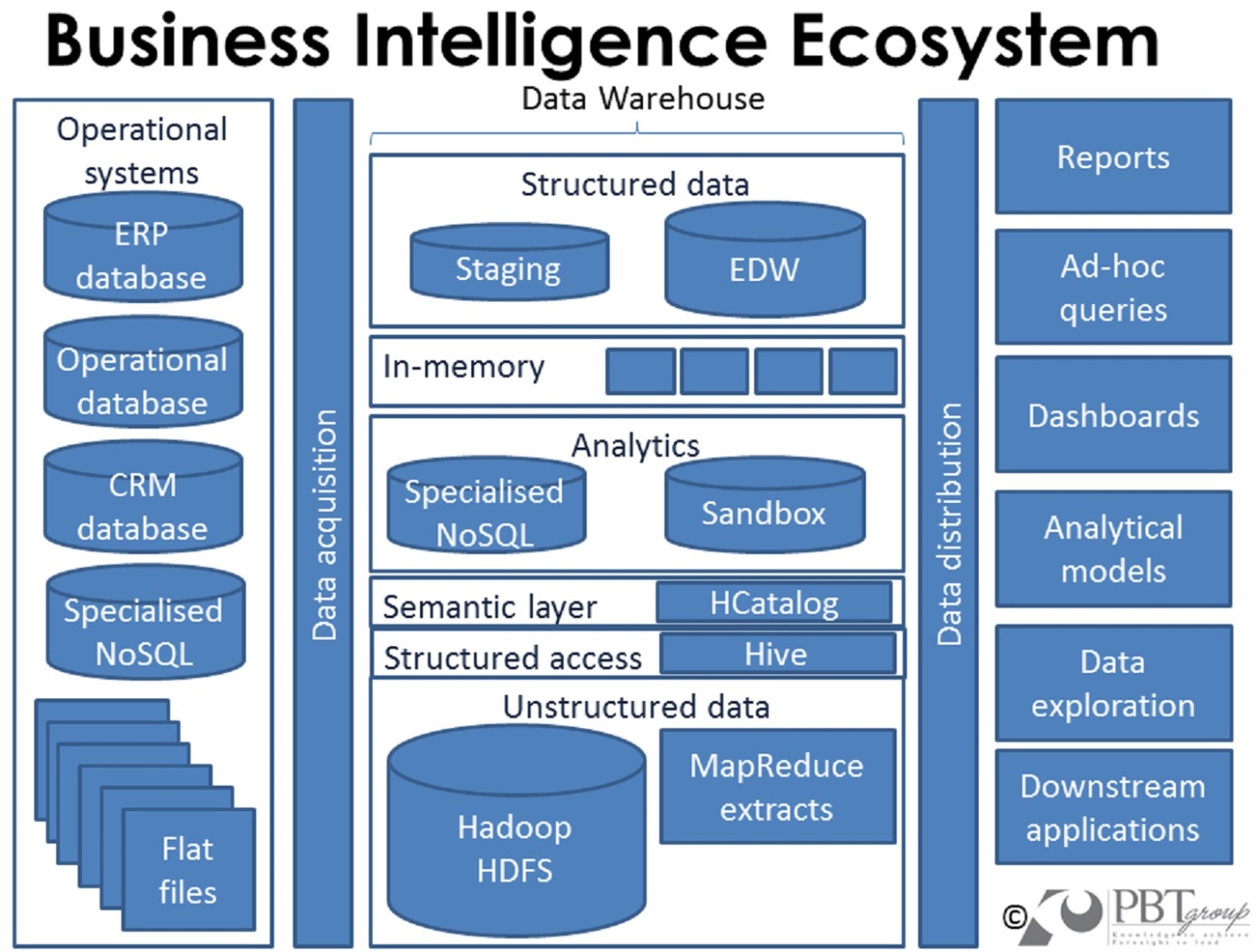
Put Big Data Value in the Hands of Analysts
- Business Inefficiencies Identified: Let analysts to view end-to-end processing of business transactions in an organization
- Business Inefficiencies Rectified: Let analysts to rectify end-to-end processing of business transactions in an organization
- Knowledge Enhancement: Provide the analyst team additional operational and business context
- Store Terabytes of Data: Provide analysts visibility into the whole infrastructure
- Enable More Data Usages: Cartel device, system, and application data to bring business operational views of IT professionals in an organization.
- Enhance Value: Pinpoint and implement newfangled opportunities that would otherwise be impossible to view and act upon
How Can You Categorize the Personal Data?
This can be categorized as volunteered data, Observed data, and Inferred data. For any enterprise to succeed in driving value from big data, volume, variety, and velocity have to be addressed in parallel.
Engineering Big Data Platforms
Big data platforms need to operate and process data at a scale that leaves little room for mistake. Big data clusters should be designed for speed, scale, and efficiency. Many businesses venturing into big data don’t have knowledge building and operating hardware and software, however, many are now confronted with that prospect. Platform consciousness enterprises will boost their productivity and churn out good results with big data.
Optimize Aspects of Business
Many enterprises are operating their businesses without any prior optimization of accurate risk analysis. Therefore, more risk analysis is required to tackle these challenges. There is a continuum of risk between aversion and recklessness, which is needed to be optimized. To some extent, risk can be averse but BI strategies can be a wonderful tool to mitigate the risk.
For handling big data, companies need to revamp their data centers, computing systems and their existing infrastructure. Be prepared for the next generation of data handling challenges and equip your organization with the latest tools and technologies to get an edge over your competitors.
Roles and Responsibilities of Big Data Professionals
Big Data professionals work dedicatedly on highly scalable and extensible platform that provides all services like gathering, storing, modeling, and analyzing massive data sets from multiple channels, mitigation of data sets, filtering and IVR, social media, chats interactions and messaging at one go. The major duties include project scheduling, design, implementation and coordination, design and develop new components of the big data platform, define and refine the big data platform, understanding the architecture, research and experiment with emerging technologies, and establish and reinforce disciplined software development processes.
Why to optimize Internet-scale platforms?
To meet up with high level of performance Internet-scale must be operated accordingly. It is important to optimize the complexity, intersection of operations, economics, and architecture. Enterprises wanted to get advantage of Big Data will fall in the internet-scale expectations of their employees, vendors, and platform on which the data is handled. A mammoth of infrastructure is needed to handle big data platforms; a single Hadoop cluster with serious punch consists of racks of servers and switches to get the bales of data onto the cluster. In this way, Internet-scale platforms are optimized to get maximum productivity and making the most of the resources fully utilized.
Dynamics of the Data Environment
A number of ecosystem elements must be in place to turn data into and economical tool. A strategic mechanism is needed to be developed to ensure adequate user privacy and security for these mobile generated data. To maximize the impact similar models could be created in the mobile ecosystem and the data generated through them.
Better Data Usages: Lessen Information Gap
Enterprises are feeling the heat of big data and they are stated to cope up with this disaster. There are two primary ways to make the Big data gathered by mobile device usage can spur effective are:
- Reduces the time lag between the start of a trend
- Reduces the knowledge gap about how people respond to these trends.
Breaking through Silos
Silos are a result of hierarchies of the organization, which require organizing people into economically effective groups. Data silos become a barrier that impedes decision-making and organizational performance. Enterprises are facing many challenges to glean insight with Big Data Analytics that trapped in the data silos exist across business operations. Through the effective handling of big data can stymie data silos and the enterprise can leverage available data into emerging customer trends or market shifts for insights and productivity.
Tremendous opportunities are there with big data as the challenges. Enterprises that are mastered in handling big data are reaping the huge chunk of profits in comparison to their competitors. The research shows that the companies, who has been taking initiatives through data directed decision making fourfold boost in their productivity; the proper use of big data goes beyond the traditional thinking like gathering and analyzing; it requires a long perspective how to make the crucial decision based on Big Data.